In statistics, imputation is the process of substituting the missing values in the data with some appropriate values. Why impute the missing value? Because statistical packages discard the...
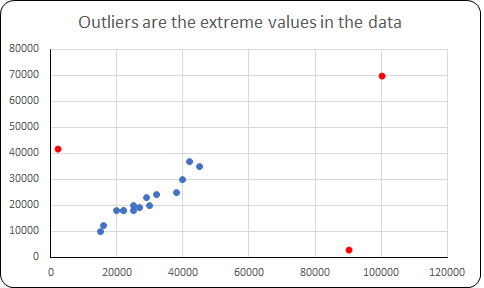 Outlier Outliers are the extreme values in the data. If the value of a variable is too large or too small, i.e, if the value is beyond a certain acceptable range then we consider that value to be an...
Outlier Outliers are the extreme values in the data. If the value of a variable is too large or too small, i.e, if the value is beyond a certain acceptable range then we consider that value to be an...
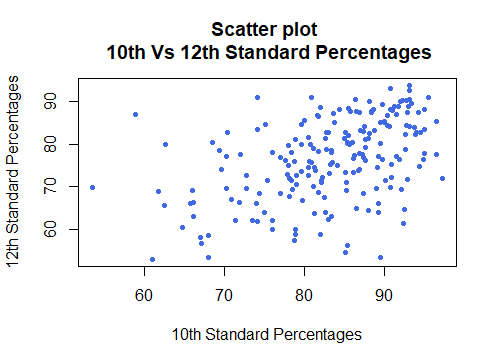 Analysis of Two Continuous Variables In the earlier blogs, we have learned about the Analysis of Single Continuous and Single Categorical variable. In this blog, we will analyze Two Continuous...
Analysis of Two Continuous Variables In the earlier blogs, we have learned about the Analysis of Single Continuous and Single Categorical variable. In this blog, we will analyze Two Continuous...
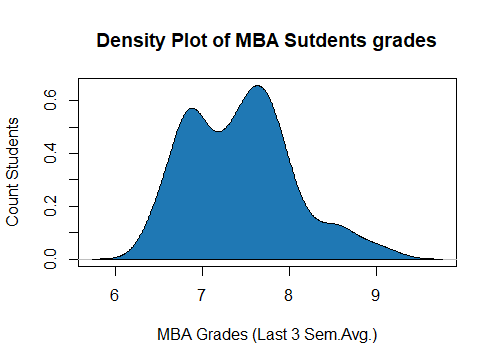 Analysis of Single Continuous Variable In our earlier blog, we learned to analyze a Single Categorical Variable in R. In this blog, we will Analyze a Single Continuous Variable in R. The below...
Analysis of Single Continuous Variable In our earlier blog, we learned to analyze a Single Categorical Variable in R. In this blog, we will Analyze a Single Continuous Variable in R. The below...
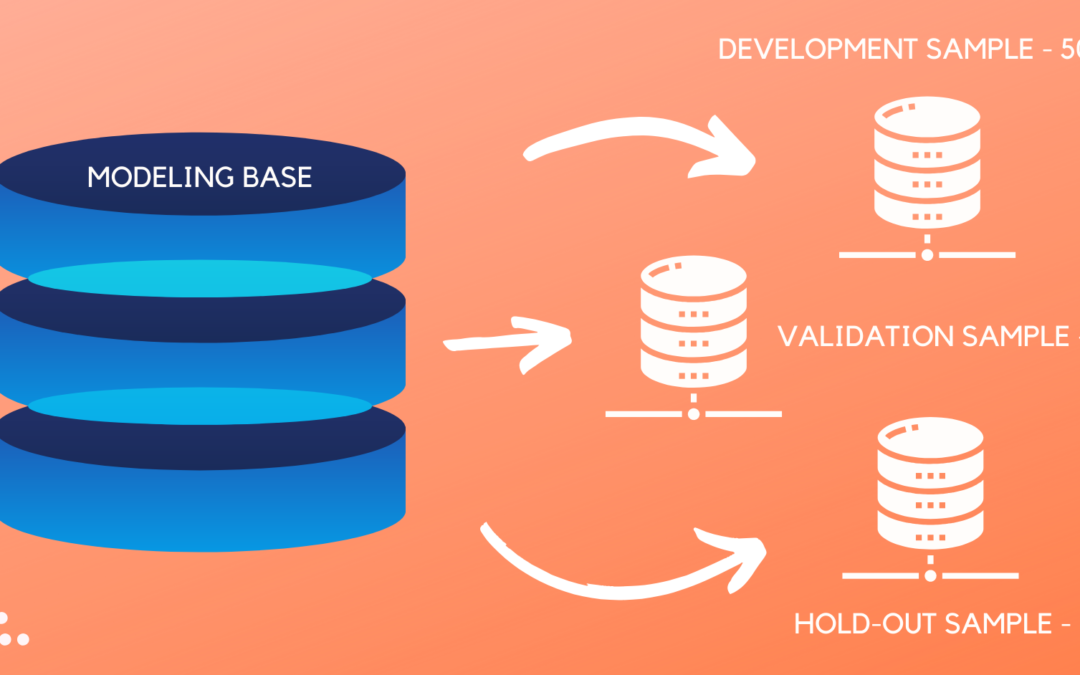 Train – Test Split Code In the previous blog, we learned that Train/Test is the method used to evaluate supervised machine learning models. Let us see how to split the data in training and...
Train – Test Split Code In the previous blog, we learned that Train/Test is the method used to evaluate supervised machine learning models. Let us see how to split the data in training and...
How can we help?
Recent Comments