
Why Clustering?
Clustering is done to group similar objects/entities.
To create homogeneous groups from heterogeneous data.
E.g. in Marketing, we create Customer Segments (Clusters) to design customized products/services/offerings at the segment level.
What is Clustering?
Clustering is the Machine Learning approach of doing Segmentation.
Clustering is a Machine Learning Technique for finding similar groups in data, called “clusters”
What is a Cluster?
A cluster can be defined as a collection of objects which are “similar” between them and are “dissimilar” to the objects belonging to other clusters
Broad Types of Clustering
• Hierarchical Clustering
• Partitioning Clustering
Code to Perform Hierarchical Clustering in R
Setting the Working Directory:
The data file we will use is “Cust_Spend_Data.csv” and it can be downloaded from the Complementary Resources section on our website. After having downloaded the file, say the file is saved in the folder “D:/K2Analytics/datafile”
> setwd ("D:/K2Analytics/datafile")
#Import Data
> RCDF <- read.csv("Cust_Spend_Data.csv", header=TRUE)
#View Data
> View(RCDF)
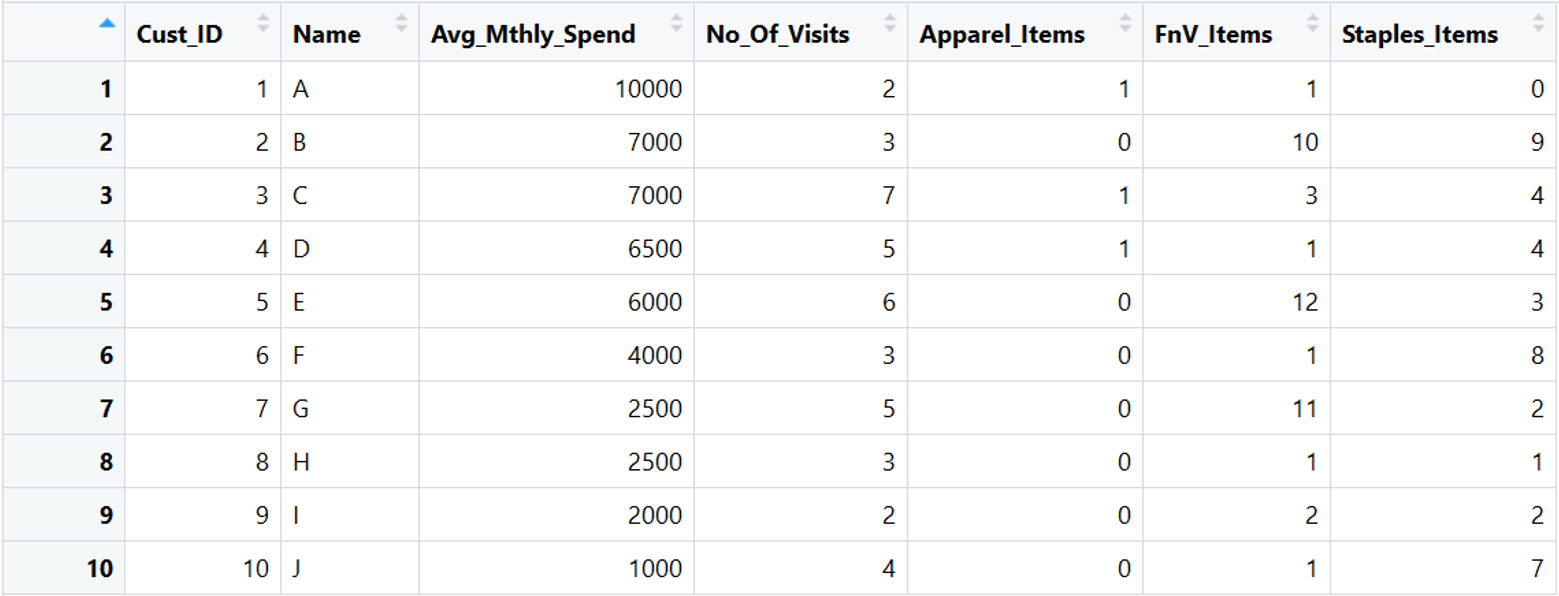
Understand Data:
The data is about Retail Customer Spends at Supermarket. The column metadata is:
• AVG_Mthly_Spend: The average monthly amount spent by the customer
• No_of_Visits: The number of times a customer visited the Supermarket in a month
• Item Counts: Count of Apparel, Fruits and Vegetable (FnV), Staple Items purchased in a month
Scale Data:
In clustering, if the data is not ordinal then we should scale the data. To scale, we can use scale() function in R which standardizes the data.
> scaled.RCDF <- scale(RCDF[,3:7])
Compute Distance:
Clustering use Distance between two objects as a measure of (dis)similarity. We will use the euclidean distance.
> d.euc <- dist(x=scaled.RCDF, method = "euclidean")
Perform Clustering:
Run Hierarchical Clustering function on the distance matrix (d.euc)
> clus <- hclust( d.euc, method = "average")
method = “average” is the linkage algorithm parameter. You can pass different values instead of “average” like “ward.D”, “ward.D2”, “single”, “complete”
The cluster output is stored in “clus” object
Plot Clustering Dendrogram
> plot(clus, labels = as.character(RCDF[,2]))
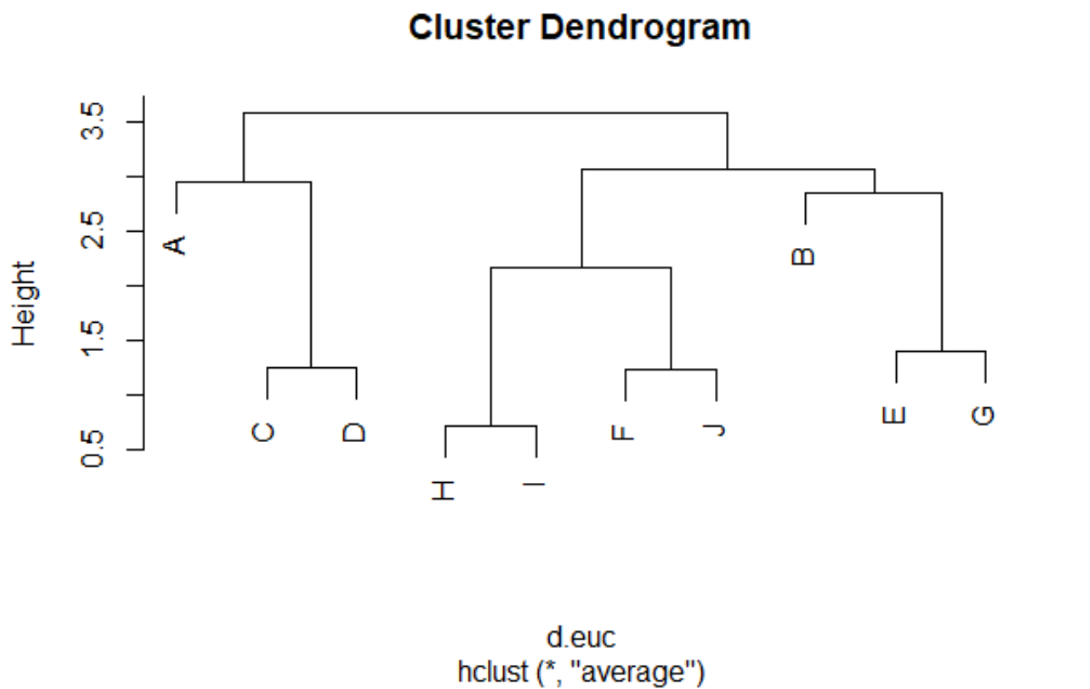
Decide the Number of Clusters
By visually seeing the Dendrogram, I feel that I should create 3 clusters from the data. There are various approaches like Scree Plot, NBClust Package in R, etc to determine the optimal number of clusters. However, for now, let us say 3 is the optimal number of clusters for our data.
For visual outcome:
> rect.hclust(clus, k=3, border="red")
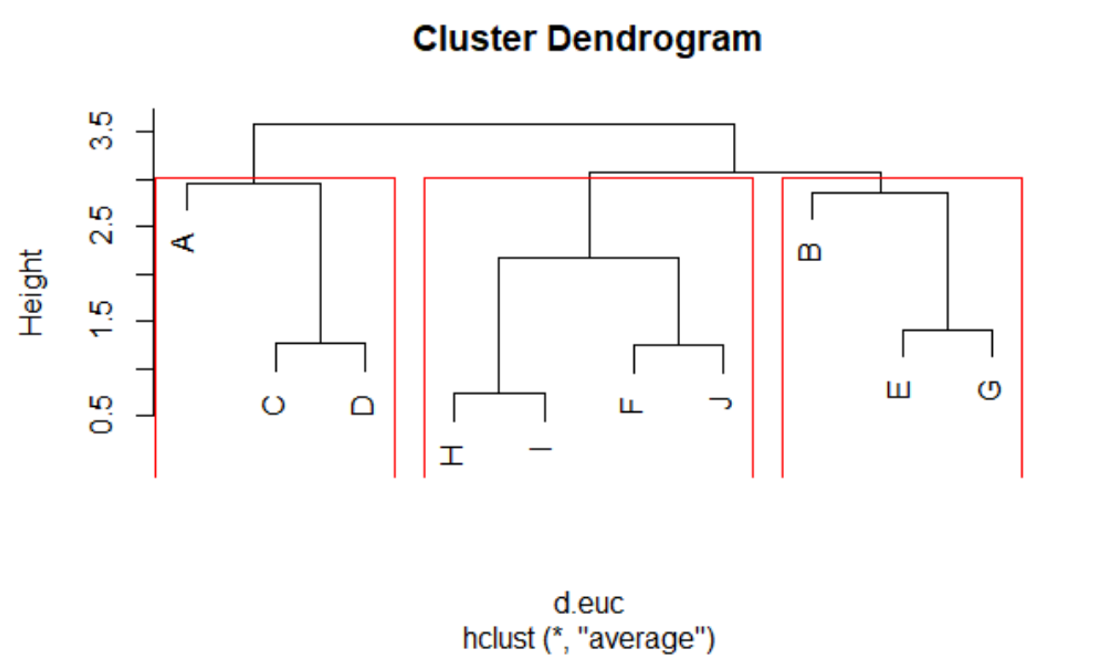
For creating cluster label in our original dataset:
> RCDF$Clusters <- cutree(clus, k=3)
Profiling the Clusters
Let us profile the clusters to understand their characteristics. It involves aggregating and summarizing data at the cluster level.
> aggr = aggregate(RCDF[,-c(1,2, 8)],list(RCDF$Clusters),mean) > clus.profile <- data.frame( Cluster=aggr[,1], Freq=as.vector(table(RCDF$Clusters)),aggr[,-1]) > View(clus.profile)

Validating the Clusters
This step is to understand the characteristics of the clusters. See if the clusters make business sense and how it can be used for Marketing or the purpose for which clustering exercise is undertaken.
From profiling we see:
1. Cluster 1 – Highest Avg. Monthly Spend. These customers 4 to 5 times in a month and have shopped in Apparel Section.
2. Cluster 2 – Moderate Avg. Monthly Spend. They come at least 4 – 5 times in a month to buy regular household items.
3. Cluster 3 – Low Spend, Low Visit Frequency, and they majorly buy staple items.
The clusters have differentiating characteristics that enables a marketer to design suitable offers and campaigns for them.
Naming the Clusters
In the end, we must give self-explanatory names to clusters. The cluster names will help in relating to the clusters. E.g. we may call Cluster 1 as Apparel Buyers, Cluster 2 as FnV Lovers, and Cluster 3 as Low-Low Segment.
Sign-Off Note: Hope you enjoyed doing clustering in R!
Suggested read – K Means clustering in R
Recent Comments