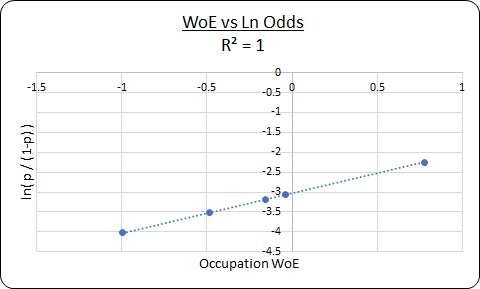
Information Value and Weight of Evidence (WoE)
Information Value and Weight of Evidence concepts are used in Logistic Regression for variable selection and variable transformation respectively.
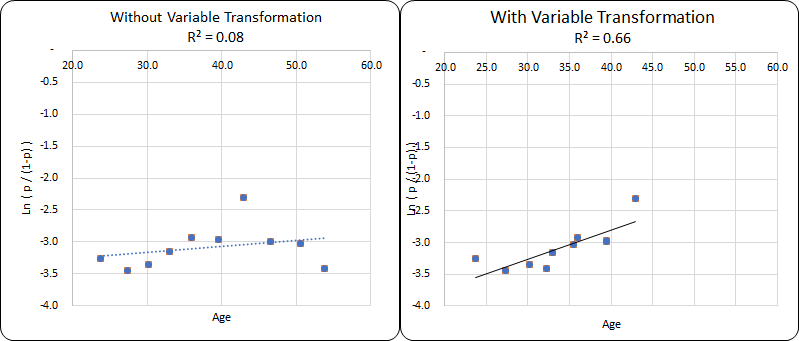
Variable Transformation in Logistic Regression
Variable Transformation refers to the replacement of a variable by some function. In logistic regression, it is done to improve the fit of the model.
Missing Value Imputation of Continuous Variable
This blog explains the missing value imputation of a continuous variable using mean, median and business logic approach along with Python code.
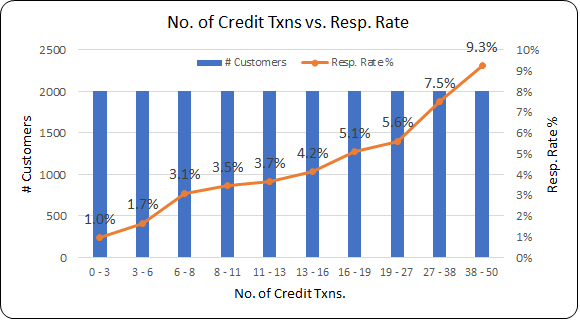
Visualization and Pattern Detection in Logistic Regression
Visualization and Pattern Detection is a very important step in Logistic Regression Model development. Visuals create the Wah!!! effect.
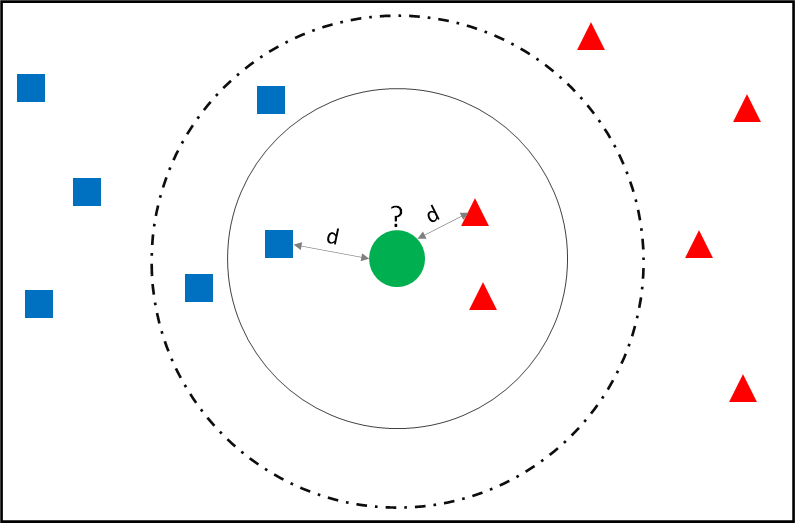
K Nearest Neighbours
KNN is the simplest of all the Supervised Machine Learning techniques. It determines the class of unclassified record from the k adjoining neighbours.
Missing Value Imputation using KNN
KNN is the simplest of all the Supervised Machine Learning techniques. One of the major applications of the KNN technique is Missing Value Imputation.
Missing Value Imputation
In statistics, imputation is the process of substituting missing values in the data with some appropriate values. Why imputation of the missing values is important?

Analysis of Two Variables – One Categorical and Other Continuous
Scatter Plot is used to see the relationship between two continuous variables. Correlation help us quantify the strength of the linear relationship between the two continuous variables
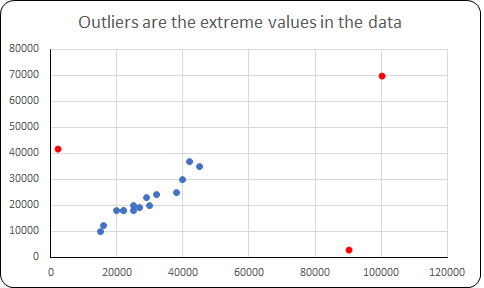
Outlier Treatment in Python and R
Outliers are the extreme values in the data. If the value of a variable is too large or too small, i.e, if the value is beyond a certain acceptable range then we consider that value to be an outlier.